Parameter Study
A parameter study is defined here as performing a simulation with varying uncertain parameters and computing quantities of interest for each set of uncertain parameters. This example is a more detailed example of what is presented in Monte Carlo Example, which is also a parameter study.
Problem Statement
To demonstrate how to perform a parameter study the transient heat equation will be used.
(1)where is temperature, is time, is diffusivity, and is a heat source term. This problem shall be solved on a 2D unit square domain. The left side is subjected to a Dirichlet condition . The right side of the domain is subject to a Neumann condition , where is the outward facing normal vector from the boundary.
The boundary conditions and as well as the diffusivity () and the source term are assumed to be known. However, these parameters have some associated uncertainty. The effect of the uncertainty on the average temperature and heat flux on the left boundary after one second of simulation time is desired, defined as and .
Heat Equation Problem
The first step in performing a parameter study is to create an input file that solves your problem without uncertain parameters. For the example problem this will be done assuming , , , and .
The complete input file for this problem is provided in Listing 1. The only item that is atypical from a MOOSE simulation input file is the existence of the Controls block, which here simply creates a SamplerReceiver object. This block is required for the parameter study, but shall be discussed in the Transfers Block section.
Listing 1: Complete input file for example heat equation problem to be used in parameter study.
[Mesh<<<{"href": "../../../syntax/Mesh/index.html"}>>>]
type = GeneratedMesh
dim = 2
nx = 10
ny = 10
[]
[Variables<<<{"href": "../../../syntax/Variables/index.html"}>>>/T]
initial_condition<<<{"description": "Specifies a constant initial condition for this variable"}>>> = 300
[]
[Kernels<<<{"href": "../../../syntax/Kernels/index.html"}>>>]
[time]
type = ADTimeDerivative<<<{"description": "The time derivative operator with the weak form of $(\\psi_i, \\frac{\\partial u_h}{\\partial t})$.", "href": "../../../source/kernels/ADTimeDerivative.html"}>>>
variable<<<{"description": "The name of the variable that this residual object operates on"}>>> = T
[]
[diff]
type = ADMatDiffusion<<<{"description": "Diffusion equation Kernel that takes an isotropic Diffusivity from a material property", "href": "../../../source/kernels/MatDiffusion.html"}>>>
variable<<<{"description": "The name of the variable that this residual object operates on"}>>> = T
diffusivity<<<{"description": "The diffusivity value or material property"}>>> = diffusivity
[]
[source]
type = ADBodyForce<<<{"description": "Demonstrates the multiple ways that scalar values can be introduced into kernels, e.g. (controllable) constants, functions, and postprocessors. Implements the weak form $(\\psi_i, -f)$.", "href": "../../../source/kernels/BodyForce.html"}>>>
variable<<<{"description": "The name of the variable that this residual object operates on"}>>> = T
value<<<{"description": "Coefficient to multiply by the body force term"}>>> = 100
function<<<{"description": "A function that describes the body force"}>>> = 1
[]
[]
[BCs<<<{"href": "../../../syntax/BCs/index.html"}>>>]
[left]
type = ADDirichletBC<<<{"description": "Imposes the essential boundary condition $u=g$, where $g$ is a constant, controllable value.", "href": "../../../source/bcs/ADDirichletBC.html"}>>>
variable<<<{"description": "The name of the variable that this residual object operates on"}>>> = T
boundary<<<{"description": "The list of boundary IDs from the mesh where this object applies"}>>> = left
value<<<{"description": "Value of the BC"}>>> = 300
[]
[right]
type = ADNeumannBC<<<{"description": "Imposes the integrated boundary condition $\\frac{\\partial u}{\\partial n}=h$, where $h$ is a constant, controllable value.", "href": "../../../source/bcs/NeumannBC.html"}>>>
variable<<<{"description": "The name of the variable that this residual object operates on"}>>> = T
boundary<<<{"description": "The list of boundary IDs from the mesh where this object applies"}>>> = right
value<<<{"description": "For a Laplacian problem, the value of the gradient dotted with the normals on the boundary."}>>> = -100
[]
[]
[Materials<<<{"href": "../../../syntax/Materials/index.html"}>>>/constant]
type = ADGenericConstantMaterial<<<{"description": "Declares material properties based on names and values prescribed by input parameters.", "href": "../../../source/materials/GenericConstantMaterial.html"}>>>
prop_names<<<{"description": "The names of the properties this material will have"}>>> = 'diffusivity'
prop_values<<<{"description": "The values associated with the named properties"}>>> = 1
[]
[Executioner<<<{"href": "../../../syntax/Executioner/index.html"}>>>]
type = Transient
num_steps = 4
dt = 0.25
[]
[Postprocessors<<<{"href": "../../../syntax/Postprocessors/index.html"}>>>]
[T_avg]
type = ElementAverageValue<<<{"description": "Computes the volumetric average of a variable", "href": "../../../source/postprocessors/ElementAverageValue.html"}>>>
variable<<<{"description": "The name of the variable that this object operates on"}>>> = T
execute_on<<<{"description": "The list of flag(s) indicating when this object should be executed. For a description of each flag, see https://mooseframework.inl.gov/source/interfaces/SetupInterface.html."}>>> = 'initial timestep_end'
[]
[q_left]
type = ADSideDiffusiveFluxAverage<<<{"description": "Computes the average of the diffusive flux over the specified boundary", "href": "../../../source/postprocessors/SideDiffusiveFluxAverage.html"}>>>
variable<<<{"description": "The name of the variable which this postprocessor integrates"}>>> = T
boundary<<<{"description": "The list of boundary IDs from the mesh where this object applies"}>>> = left
diffusivity<<<{"description": "The name of the diffusivity material property that will be used in the flux computation. This must be provided if the variable is of finite element type"}>>> = diffusivity
execute_on<<<{"description": "The list of flag(s) indicating when this object should be executed. For a description of each flag, see https://mooseframework.inl.gov/source/interfaces/SetupInterface.html."}>>> = 'initial timestep_end'
[]
[]
[Controls<<<{"href": "../../../syntax/Controls/index.html"}>>>/stochastic]
type = SamplerReceiver<<<{"description": "Control for receiving data from a Sampler via SamplerParameterTransfer.", "href": "../../../source/controls/SamplerReceiver.html"}>>>
[]
[Outputs<<<{"href": "../../../syntax/Outputs/index.html"}>>>]
[]Executing this file using the StochasticToolsApp can be done as follows
cd moose/modules/stochastic_tools/examples/parameter_study
../../stochastic_tools-opt -i diffusion.i
The simulation will perform four timesteps and should result in and .
Main Input
To perform a parameter study an input file that will drive the stochastic simulations is required. This file will be referred to as the main input file and is responsible for defining the uncertain parameters, running the stochastic simulations, and collecting the stochastic results. The following sub-sections will step through each portion of the main file to explain the purpose. The complete analysis is discussed in Stochastic Results.
The specific parameter study performed in this tutorial can also done using the ParameterStudy syntax, shown in the code block below. However, it is very useful to learn each aspect of doing a stochastic simulation in the stochastic tools module, which is described in the following sub-sections.
Parameter study using ParameterStudy input block
[ParameterStudy<<<{"href": "../../../syntax/ParameterStudy/index.html"}>>>]
input<<<{"description": "The input file containing the physics for the parameter study."}>>> = diffusion.i
parameters<<<{"description": "List of parameters being perturbed for the study."}>>> = 'Materials/constant/prop_values Kernels/source/value BCs/right/value BCs/left/value'
quantities_of_interest<<<{"description": "List of the reporter names (object_name/value_name) that represent the quantities of interest for the study."}>>> = 'T_avg/value q_left/value'
sampling_type<<<{"description": "The type of sampling to use for the parameter study."}>>> = lhs
num_samples<<<{"description": "The number of samples to generate for 'monte-carlo' and 'lhs' sampling."}>>> = 5000
distributions<<<{"description": "The types of distribution to use for 'monte-carlo' and 'lhs' sampling. The number of entries defines the number of columns in the matrix."}>>> = 'uniform weibull normal normal'
uniform_lower_bound<<<{"description": "Lower bounds for 'uniform' distributions."}>>> = 0.5
uniform_upper_bound<<<{"description": "Upper bounds 'uniform' distributions."}>>> = 2.5
weibull_location<<<{"description": "Location parameter (a or low) for 'weibull' distributions."}>>> = -110
weibull_scale<<<{"description": "Scale parameter (b or lambda) for 'weibull' distributions."}>>> = 20
weibull_shape<<<{"description": "Shape parameter (c or k) for 'weibull' distributions."}>>> = 1
normal_mean<<<{"description": "Means (or expectations) of the 'normal' distributions."}>>> = '300 100'
normal_standard_deviation<<<{"description": "Standard deviations of the 'normal' distributions."}>>> = '45 25'
[]StochasticTools Block
The StochasticTools block sets up the main file to be a driver for stochastic simulations but itself is not performing any sort of simulation. Setting up a main application without a simulation itself is the default behavior for this block, as such it is empty in this example.
[StochasticTools<<<{"href": "../../../syntax/StochasticTools/index.html"}>>>]
[]Distributions and Samplers Blocks
The Distributions block defines the statistical distribution for each of the uncertain parameters (, , , and ) to be defined. For this example, the diffusivity () is defined by a uniform distribution, the flux () by a three-parameter Weibull, and and a normal distribution.
[Distributions<<<{"href": "../../../syntax/Distributions/index.html"}>>>]
[gamma]
type = Uniform<<<{"description": "Continuous uniform distribution.", "href": "../../../source/distributions/Uniform.html"}>>>
lower_bound<<<{"description": "Distribution lower bound"}>>> = 0.5
upper_bound<<<{"description": "Distribution upper bound"}>>> = 2.5
[]
[q_0]
type = Weibull<<<{"description": "Three-parameter Weibull distribution.", "href": "../../../source/distributions/Weibull.html"}>>>
location<<<{"description": "Location parameter (a or low)"}>>> = -110
scale<<<{"description": "Scale parameter (b or lambda)"}>>> = 20
shape<<<{"description": "Shape parameter (c or k)"}>>> = 1
[]
[T_0]
type = Normal<<<{"description": "Normal distribution", "href": "../../../source/distributions/Normal.html"}>>>
mean<<<{"description": "Mean (or expectation) of the distribution."}>>> = 300
standard_deviation<<<{"description": "Standard deviation of the distribution "}>>> = 45
[]
[s]
type = Normal<<<{"description": "Normal distribution", "href": "../../../source/distributions/Normal.html"}>>>
mean<<<{"description": "Mean (or expectation) of the distribution."}>>> = 100
standard_deviation<<<{"description": "Standard deviation of the distribution "}>>> = 25
[]
[]The Samplers block defines how the distributions shall be sampled for the parameter study. In this case a Latin hypercube sampling strategy is employed. A total of 5000 samples are being used.
[Samplers<<<{"href": "../../../syntax/Samplers/index.html"}>>>]
[hypercube]
type = LatinHypercube<<<{"description": "Latin Hypercube Sampler.", "href": "../../../source/samplers/LatinHypercubeSampler.html"}>>>
num_rows<<<{"description": "The size of the square matrix to generate."}>>> = 5000
distributions<<<{"description": "The distribution names to be sampled, the number of distributions provided defines the number of columns per matrix."}>>> = 'gamma q_0 T_0 s'
[]
[]For this problem the Sampler object is setup to run in "batch-restore" mode, which is a mode of operation for memory efficient creation of sub-applications. Please see Stochastic Tools Batch Mode for more information.
The input distributions for each of these four terms are included in Figure 1–Figure 4 for 5000 samples.
Figure 1: Input distribution of diffusivity ().
Figure 2: Input distribution of flux boundary condition ().
Figure 3: Input distribution of temperature boundary condition ().
Figure 4: Input distribution of source term ().
Transfers Block
The Transfers block serves two purposes. First, the "parameters" sub-block instantiates a SamplerParameterTransfer object that transfers each row of data from the Sampler object to a sub-application simulation. Within the sub-application the parameters listed in this sub-block replace the values in the sub-application. This substitution occurs using the aforementioned SamplerReceiver object that exists in the Controls block of the sub-application input file. The receiver on the sub-application accepts the parameter names and values from the SamplerParameterTransfer object on the main application.
The "results" sub-block serves the second purpose by transferring the quantities of interest back to the main application. In this case those quantities are postprocessors on the sub-application that compute and . These computed results are transferred from the sub-application to a StochasticReporter object (as discussed next).
[Transfers<<<{"href": "../../../syntax/Transfers/index.html"}>>>]
[parameters]
type = SamplerParameterTransfer<<<{"description": "Copies Sampler data to a SamplerReceiver object.", "href": "../../../source/transfers/SamplerParameterTransfer.html"}>>>
to_multi_app<<<{"description": "The name of the MultiApp to transfer the data to"}>>> = runner
sampler<<<{"description": "A the Sampler object that Transfer is associated.."}>>> = hypercube
parameters<<<{"description": "A list of parameters (on the sub application) to control with the Sampler data. The order of the parameters listed here should match the order of the items in the Sampler."}>>> = 'Materials/constant/prop_values Kernels/source/value BCs/right/value BCs/left/value'
[]
[results]
type = SamplerReporterTransfer<<<{"description": "Transfers data from Reporters on the sub-application to a StochasticReporter on the main application.", "href": "../../../source/transfers/SamplerReporterTransfer.html"}>>>
from_multi_app<<<{"description": "The name of the MultiApp to receive data from"}>>> = runner
sampler<<<{"description": "A the Sampler object that Transfer is associated.."}>>> = hypercube
stochastic_reporter<<<{"description": "The name of the StochasticReporter object to transfer values to."}>>> = results
from_reporter<<<{"description": "The name(s) of the Reporter(s) on the sub-app to transfer from."}>>> = 'T_avg/value q_left/value'
[]
[]Reporters Block
The Reporters block, as mentioned above, is used to collect the stochastic results. The "results" sub-block instantiates a StochasticReporter object, which is designed for this purpose. The resulting object will contain a vector for each of the quantities of interest: and .
The StatisticsReporter object is designed to compute multiple statistics and confidence intervals for each of the input vectors. In this case it computes the mean and standard deviation for and vectors in the "results" object as well as the 5% and 95% confidence level intervals. Please refer to the documentation for the StatisticsReporter object for further documentation and capabilities for this object.
[Reporters<<<{"href": "../../../syntax/Reporters/index.html"}>>>]
[results]
type = StochasticReporter<<<{"description": "Storage container for stochastic simulation results coming from Reporters.", "href": "../../../source/reporters/StochasticReporter.html"}>>>
[]
[stats]
type = StatisticsReporter<<<{"description": "Compute statistical values of a given VectorPostprocessor objects and vectors.", "href": "../../../source/reporters/StatisticsReporter.html"}>>>
reporters<<<{"description": "List of Reporter values to utilized for statistic computations."}>>> = 'results/results:T_avg:value results/results:q_left:value'
compute<<<{"description": "The statistic(s) to compute for each of the supplied vector postprocessors."}>>> = 'mean stddev'
ci_method<<<{"description": "The method to use for computing confidence level intervals."}>>> = 'percentile'
ci_levels<<<{"description": "A vector of confidence levels to consider, values must be in (0, 1)."}>>> = '0.05 0.95'
[]
[]Outputs Block
The Outputs block enables the output of the Reporter data using JSON files, see JSON for more details.
[Outputs<<<{"href": "../../../syntax/Outputs/index.html"}>>>]
execute_on<<<{"description": "The list of flag(s) indicating when this object should be executed. For a description of each flag, see https://mooseframework.inl.gov/source/interfaces/SetupInterface.html."}>>> = 'FINAL'
[out]
type = JSON<<<{"description": "Output for Reporter values using JSON format.", "href": "../../../source/outputs/JSONOutput.html"}>>>
[]
[]Stochastic Results
The input file described in the previous section can be run with the following command:
mpiexec -n <n> ../../stochastic_tools-opt -i main.i
The <n> is the number of processors to be run with. It is recommended to use a number greater than 8 to finish the calculation in a reasonable amount of time. The result will be an output of a main_out.json* file (one for each processor). If only one file is desired use the option Reporters/results/parallel_type=ROOT.
Quantity of Interest Distributions
The resulting distributions are for the quantities of interest: and are presented in Figure 5 and Figure 6. These plots were generated using the following commands:
python ../../python/moose_stochastic_tools/make_histogram.py main_out.json* -v results:T_avg:value --xlabel 'Average Temperature'
python ../../python/moose_stochastic_tools/make_histogram.py main_out.json* -v results:q_left:value --xlabel 'Flux'
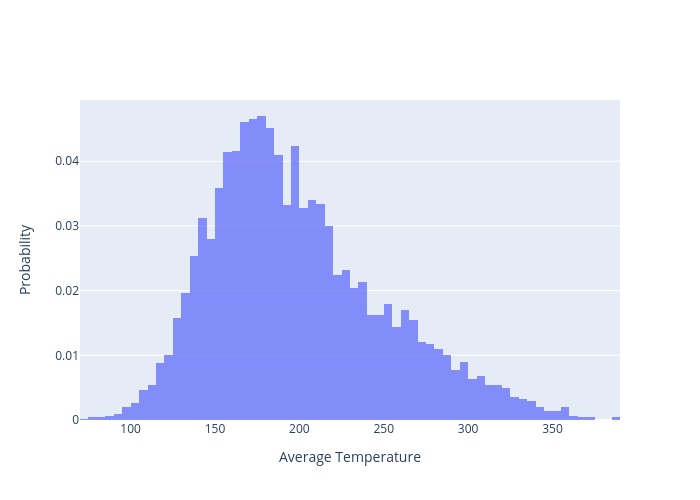
Figure 5: Resulting distribution of quantity of interest: .
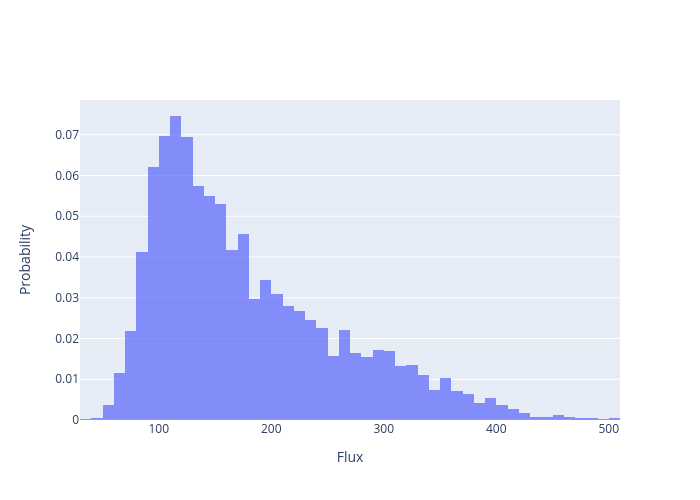
Figure 6: Resulting distribution of quantity of interest: .
Statistics
Table 1 includes the computed statistics and confidence level intervals as computed by the StatisticsReporter object for the example heat conduction problem with 5000 samples. This table was generated in markdown format using the following command:
python ../../python/moose_stochastic_tools/visualize_statistics.py main_out.json --markdown-table \
--names '{"results_results:T_avg:value":"$T_{avg}$","results_results:q_left:value":"$q_{left}$"}' \
--stat-names '{"MEAN":"Mean","STDDEV":"Standard Deviation"}'
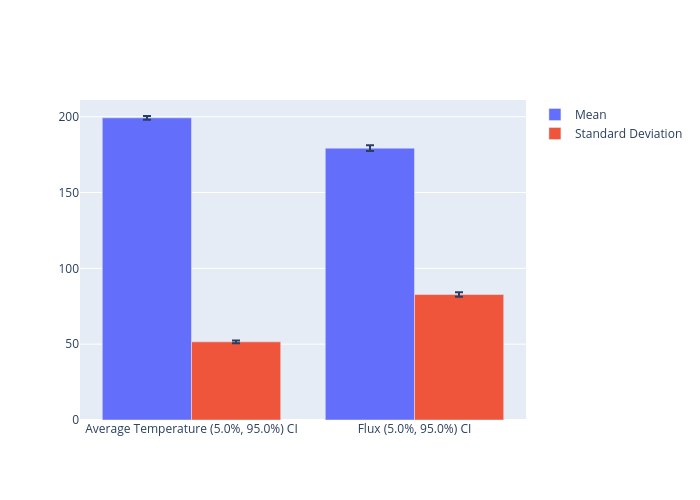
Table 1:
| Values | Mean | Standard Deviation |
|---|---|---|
| (5.0%, 95.0%) CI | 198.9 (197.7, 200) | 50.82 (49.98, 51.66) |
| (5.0%, 95.0%) CI | 178.5 (176.6, 180.4) | 79.97 (78.55, 81.4) |
These statistics can also be visualized with a bar plot:
python ../../python/moose_stochastic_tools/visualize_statistics.py main_out.json --bar-plot \
--names '{"results_results:T_avg:value":"Average Temperature","results_results:q_left:value":"Flux"}' \
--stat-names '{"MEAN":"Mean","STDDEV":"Standard Deviation"}'
Time Dependent and Vector Quantities
Often, it is useful to perform parameter studies with quantities that are time-dependent. This section will show how to modify the previous inputs for quantities that are time-dependent or possibly vectors.
Sub-application Input Modifications
The only change to the sub-app input is the addition of a LineValueSampler vector-postprocessor that computes the spatial distribution of the temperature.
[VectorPostprocessors<<<{"href": "../../../syntax/VectorPostprocessors/index.html"}>>>]
[T_vec]
type = LineValueSampler<<<{"description": "Samples variable(s) along a specified line", "href": "../../../source/vectorpostprocessors/LineValueSampler.html"}>>>
variable<<<{"description": "The names of the variables that this VectorPostprocessor operates on"}>>> = T
start_point<<<{"description": "The beginning of the line"}>>> = '0 0.5 0'
end_point<<<{"description": "The ending of the line"}>>> = '1 0.5 0'
num_points<<<{"description": "The number of points to sample along the line"}>>> = 11
sort_by<<<{"description": "What to sort the samples by. Options include 'x', 'y', 'z', 'id', and the name of any of the sampled quantities (which each create a vector of the same name)."}>>> = x
execute_on<<<{"description": "The list of flag(s) indicating when this object should be executed. For a description of each flag, see https://mooseframework.inl.gov/source/interfaces/SetupInterface.html."}>>> = 'initial timestep_end'
[]
[]Main Input Modifications
The two significant modifications to the main input is the change to a SamplerTransientMultiApp and the addition of the Executioner block. The combination of these two blocks will run the sampled sub-applications in tandem with the time-step defined in the main input. The main application in this case will "drive" the overall simulation (and does support sub-cycling). Here, we use the same time stepping as in the sub-application.
[MultiApps<<<{"href": "../../../syntax/MultiApps/index.html"}>>>]
[runner]
type = SamplerTransientMultiApp<<<{"description": "Creates a sub-application for each row of each Sampler matrix.", "href": "../../../source/multiapps/SamplerTransientMultiApp.html"}>>>
sampler<<<{"description": "The Sampler object to utilize for creating MultiApps."}>>> = hypercube
input_files<<<{"description": "The input file for each App. If this parameter only contains one input file it will be used for all of the Apps. When using 'positions_from_file' it is also admissable to provide one input_file per file."}>>> = 'diffusion_time.i'
mode<<<{"description": "The operation mode, 'normal' creates one sub-application for each row in the Sampler and 'batch-reset' and 'batch-restore' creates N sub-applications, where N is the minimum of 'num_rows' in the Sampler and floor(number of processes / min_procs_per_app). To run the rows in the Sampler, 'batch-reset' will destroy and re-create sub-apps as needed, whereas the 'batch-restore' will backup and restore sub-apps to the initial state prior to execution, without destruction."}>>> = batch-restore
[]
[]
[Executioner<<<{"href": "../../../syntax/Executioner/index.html"}>>>]
type = Transient
num_steps = 4
dt = 0.25
[]We will also add the transfer for the LineValueSampler included in the sub input, while also computing statistics and transferring the x-coord values. Note that the ConstantReporter is just a place holder for the MultiAppReporterTransfer to transfer the x-coord data into.
[Transfers<<<{"href": "../../../syntax/Transfers/index.html"}>>>]
[parameters]
type = SamplerParameterTransfer<<<{"description": "Copies Sampler data to a SamplerReceiver object.", "href": "../../../source/transfers/SamplerParameterTransfer.html"}>>>
to_multi_app<<<{"description": "The name of the MultiApp to transfer the data to"}>>> = runner
sampler<<<{"description": "A the Sampler object that Transfer is associated.."}>>> = hypercube
parameters<<<{"description": "A list of parameters (on the sub application) to control with the Sampler data. The order of the parameters listed here should match the order of the items in the Sampler."}>>> = 'Materials/constant/prop_values Kernels/source/value BCs/right/value BCs/left/value'
[]
[results]
type = SamplerReporterTransfer<<<{"description": "Transfers data from Reporters on the sub-application to a StochasticReporter on the main application.", "href": "../../../source/transfers/SamplerReporterTransfer.html"}>>>
from_multi_app<<<{"description": "The name of the MultiApp to receive data from"}>>> = runner
sampler<<<{"description": "A the Sampler object that Transfer is associated.."}>>> = hypercube
stochastic_reporter<<<{"description": "The name of the StochasticReporter object to transfer values to."}>>> = results
from_reporter<<<{"description": "The name(s) of the Reporter(s) on the sub-app to transfer from."}>>> = 'T_avg/value q_left/value T_vec/T'
[]
[x_transfer]
type = MultiAppReporterTransfer<<<{"description": "Transfers reporter data between two applications.", "href": "../../../source/transfers/MultiAppReporterTransfer.html"}>>>
from_multi_app<<<{"description": "The name of the MultiApp to receive data from"}>>> = runner
subapp_index<<<{"description": "The MultiApp object sub-application index to use when transferring to/from the sub-application. If unset and transferring to the sub-applications then all sub-applications will receive data. The value must be set when transferring from a sub-application."}>>> = 0
from_reporters<<<{"description": "List of the reporter names (object_name/value_name) to transfer the value from."}>>> = T_vec/x
to_reporters<<<{"description": "List of the reporter names (object_name/value_name) to transfer the value to."}>>> = const/x
[]
[]
[Reporters<<<{"href": "../../../syntax/Reporters/index.html"}>>>]
[results]
type = StochasticReporter<<<{"description": "Storage container for stochastic simulation results coming from Reporters.", "href": "../../../source/reporters/StochasticReporter.html"}>>>
outputs<<<{"description": "Vector of output names where you would like to restrict the output of variables(s) associated with this object"}>>> = none
[]
[stats]
type = StatisticsReporter<<<{"description": "Compute statistical values of a given VectorPostprocessor objects and vectors.", "href": "../../../source/reporters/StatisticsReporter.html"}>>>
reporters<<<{"description": "List of Reporter values to utilized for statistic computations."}>>> = 'results/results:T_avg:value results/results:q_left:value results/results:T_vec:T'
compute<<<{"description": "The statistic(s) to compute for each of the supplied vector postprocessors."}>>> = 'mean stddev'
ci_method<<<{"description": "The method to use for computing confidence level intervals."}>>> = 'percentile'
ci_levels<<<{"description": "A vector of confidence levels to consider, values must be in (0, 1)."}>>> = '0.05 0.95'
[]
[const]
type = ConstantReporter<<<{"description": "Reporter with constant values to be accessed by other objects, can be modified using transfers.", "href": "../../../source/reporters/ConstantReporter.html"}>>>
real_vector_names<<<{"description": "Names for each vector of reals value."}>>> = 'x'
real_vector_values<<<{"description": "Values for vectors of reals."}>>> = '0'
[]
[]Statistics
The output (main_time_out.json) will now have statistics for all three quantities for each time step. We can report this data using the following:
python ../../python/moose_stochastic_tools/visualize_statistics.py main_time_out.json --markdown-table \
--values results_results:T_avg:value results_results:q_left:value \
--names '{"results_results:T_avg:value":"Average Temperature","results_results:q_left:value":"Flux"}' \
--stats MEAN STDDEV --stat-names '{"MEAN":"Mean","STDDEV":"Standard Deviation"}'
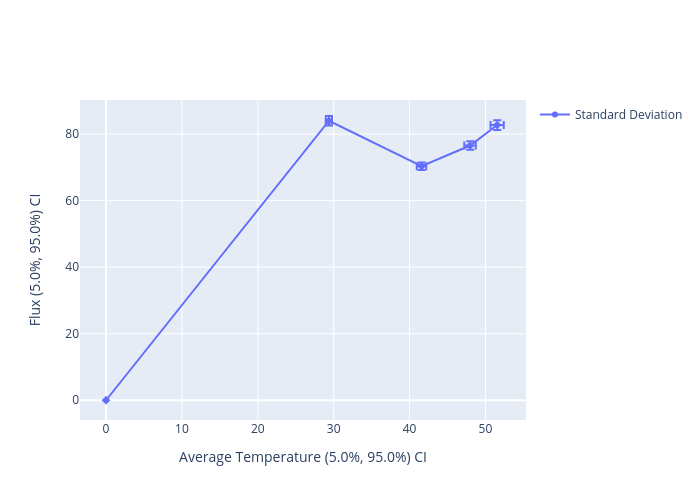
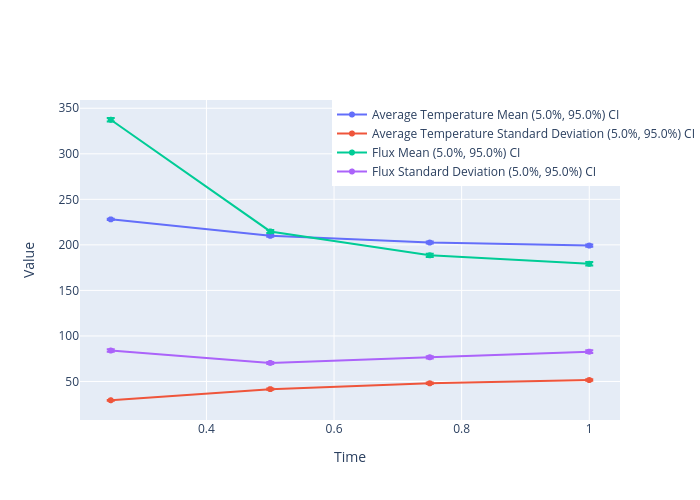
| Values | Time | Mean | Standard Deviation |
|---|---|---|---|
| Average Temperature (5.0%, 95.0%) CI | 0.25 | 227.9 (227.2, 228.5) | 29.26 (28.85, 29.67) |
| 0.5 | 209.7 (208.7, 210.6) | 41.22 (40.61, 41.83) | |
| 0.75 | 202.2 (201.1, 203.3) | 47.42 (46.67, 48.16) | |
| 1 | 198.9 (197.7, 200) | 50.82 (49.98, 51.66) | |
| Flux (5.0%, 95.0%) CI | 0.25 | 337 (335.1, 338.9) | 81.95 (80.6, 83.31) |
| 0.5 | 214.3 (212.7, 215.9) | 68.32 (67.24, 69.37) | |
| 0.75 | 188 (186.2, 189.7) | 74.18 (72.96, 75.41) | |
| 1 | 178.5 (176.6, 180.4) | 79.97 (78.55, 81.4) |
python ../../python/moose_stochastic_tools/visualize_statistics.py main_time_out.json --line-plot \
--values results_results:T_avg:value results_results:q_left:value \
--names '{"results_results:T_avg:value":"Average Temperature","results_results:q_left:value":"Flux"}' \
--stats MEAN STDDEV --stat-names '{"MEAN":"Mean","STDDEV":"Standard Deviation"}'
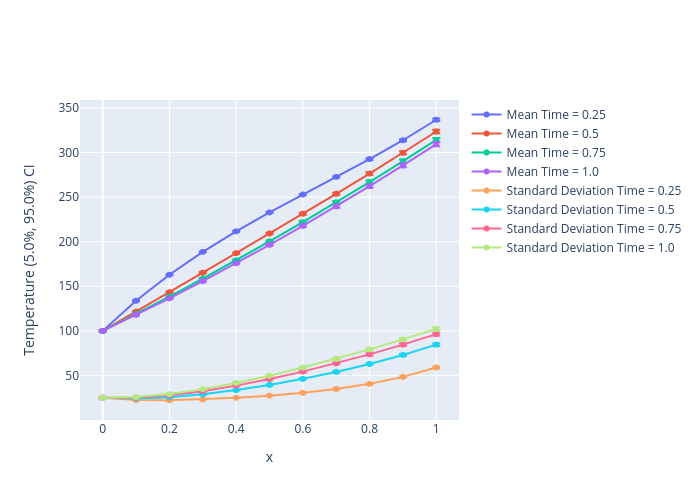
python ../../python/moose_stochastic_tools/visualize_statistics.py main_time_out.json --line-plot \
--values results_results:T_vec:T --names '{"results_results:T_vec:T":"Temperature"}' \
--stats MEAN STDDEV --stat-names '{"MEAN":"Mean","STDDEV":"Standard Deviation"}' \
--xvalue x
Time Dependent Quantities with AccumulateReporter
You might find that using SamplerTransientMultiApp, like in the previous sections, is a bit restrictive. For instance, the time steps in the sub-app input must be defined by the steps in the main input. This restricts the use of TimeSteppers like IterationAdaptiveDT and sub-cycling sub-sub-apps becomes difficult. Also, SamplerTransientMultiApp does not support batch-reset mode, so there isn't a memory-efficient way of sampling with MultiAppSamplerControl.
An alternative to using SamplerTransientMultiApp is to leverage AccumulateReporter, which accumulates postprocessors/vector-postprocessor/reporters into vector where each element is the value at a certain time-step.
Sub-application Input Modifications
For this example, we will accumulate the T_avg and q_left postprocessors. We can accumulate T_vec from the previous section, but StatisticsReporter does not yet support vector-of-vector quantities.
[Reporters<<<{"href": "../../../syntax/Reporters/index.html"}>>>]
[acc]
type = AccumulateReporter<<<{"description": "Reporter which accumulates the value of a inputted reporter value over time into a vector reporter value of the same type.", "href": "../../../source/reporters/AccumulateReporter.html"}>>>
reporters<<<{"description": "The reporters to accumulate."}>>> = 'T_avg/value q_left/value'
[]
[]Main Input Modifications
There are no major modifications to the main input from the first section. We only need to replace the transferred values from *:value to acc:*:value.
[Transfers<<<{"href": "../../../syntax/Transfers/index.html"}>>>]
[parameters]
type = SamplerParameterTransfer<<<{"description": "Copies Sampler data to a SamplerReceiver object.", "href": "../../../source/transfers/SamplerParameterTransfer.html"}>>>
to_multi_app<<<{"description": "The name of the MultiApp to transfer the data to"}>>> = runner
sampler<<<{"description": "A the Sampler object that Transfer is associated.."}>>> = hypercube
parameters<<<{"description": "A list of parameters (on the sub application) to control with the Sampler data. The order of the parameters listed here should match the order of the items in the Sampler."}>>> = 'Materials/constant/prop_values Kernels/source/value BCs/right/value BCs/left/value'
[]
[results]
type = SamplerReporterTransfer<<<{"description": "Transfers data from Reporters on the sub-application to a StochasticReporter on the main application.", "href": "../../../source/transfers/SamplerReporterTransfer.html"}>>>
from_multi_app<<<{"description": "The name of the MultiApp to receive data from"}>>> = runner
sampler<<<{"description": "A the Sampler object that Transfer is associated.."}>>> = hypercube
stochastic_reporter<<<{"description": "The name of the StochasticReporter object to transfer values to."}>>> = results
from_reporter<<<{"description": "The name(s) of the Reporter(s) on the sub-app to transfer from."}>>> = 'acc/T_avg:value acc/q_left:value'
[]
[]
[Reporters<<<{"href": "../../../syntax/Reporters/index.html"}>>>]
[results]
type = StochasticReporter<<<{"description": "Storage container for stochastic simulation results coming from Reporters.", "href": "../../../source/reporters/StochasticReporter.html"}>>>
outputs<<<{"description": "Vector of output names where you would like to restrict the output of variables(s) associated with this object"}>>> = none
[]
[stats]
type = StatisticsReporter<<<{"description": "Compute statistical values of a given VectorPostprocessor objects and vectors.", "href": "../../../source/reporters/StatisticsReporter.html"}>>>
reporters<<<{"description": "List of Reporter values to utilized for statistic computations."}>>> = 'results/results:acc:T_avg:value results/results:acc:q_left:value'
compute<<<{"description": "The statistic(s) to compute for each of the supplied vector postprocessors."}>>> = 'mean stddev'
ci_method<<<{"description": "The method to use for computing confidence level intervals."}>>> = 'percentile'
ci_levels<<<{"description": "A vector of confidence levels to consider, values must be in (0, 1)."}>>> = '0.05 0.95'
[]
[]Statistics
The output (main_vector_out.json) has the statistics for each quantity represented by a vector. All of the previous results can be reproduced with this output. One fancy thing we can do with this new output:
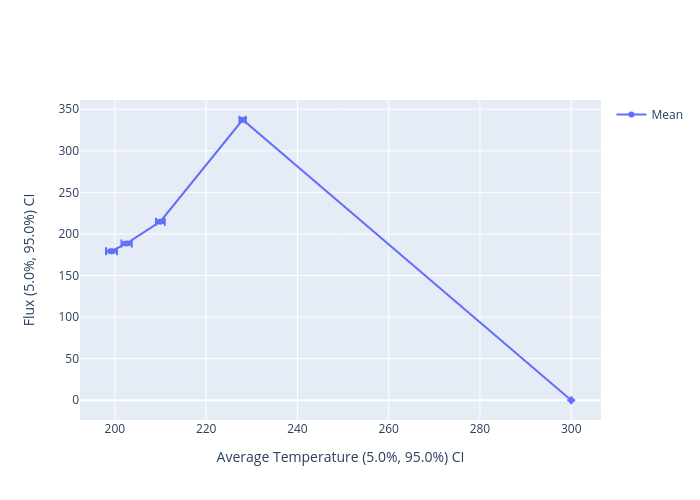
python ../../python/moose_stochastic_tools/visualize_statistics.py main_vector_out.json --line-plot \
--names '{"results_results:acc:T_avg:value":"Average Temperature","results_results:acc:q_left:value":"Flux"}' \
--xvalue results_results:acc:T_avg:value \
--stats MEAN --stat-names '{"MEAN":"Mean"}'
python ../../python/moose_stochastic_tools/visualize_statistics.py main_vector_out.json --line-plot \
--names '{"results_results:acc:T_avg:value":"Average Temperature","results_results:acc:q_left:value":"Flux"}' \
--xvalue results_results:acc:T_avg:value \
--stats STDDEV --stat-names '{"STDDEV":"Standard Deviation"}'